


Big O Explicado
Um algoritmo aparentemente “rápido” pode ficar milhares de vezes mais lento apenas porque a quantidade de dados aumentou. Esse é o detalhe que destrói sistemas em produção silenciosamente. O código funciona perfeitamente durante testes pequenos, passa em validações internas e parece elegante no GitHub. Então chega o mundo real, entram milhões de registros, usuários simultâneos, loops desnecessários e consultas mal planejadas. Nesse momento, Big O Notation deixa de ser teoria acadêmica e vira sobrevivência computacional.
A maioria dos iniciantes acredita que desempenho depende apenas de hardware mais forte. Mas programadores experientes sabem que um algoritmo ruim consegue transformar até servidores absurdamente caros em torradeiras digitais sofisticadas. O problema raramente começa na máquina. Começa na complexidade algorítmica. E é exatamente aqui que entra Big O Notation, uma das ideias mais importantes da Ciência da Computação moderna.
O que é Big O Notation na prática
Big O Notation é uma forma matemática de medir como o custo computacional de um algoritmo cresce conforme a entrada aumenta. Em termos simples, ela responde a pergunta mais importante do desenvolvimento de software em larga escala: “o que acontece quando os dados crescem absurdamente?”
Essa análise normalmente mede:
- tempo de execução;
- número de operações;
- consumo de memória;
- escalabilidade.
Na minha experiência como professor em universidade, muitos estudantes entendem loops, arrays e funções, mas demoram para perceber que a verdadeira dificuldade da computação não está apenas em fazer o código funcionar. O desafio real é fazê-lo continuar funcionando quando o volume de dados explode.
Donald Knuth, autor de The Art of Computer Programming, frequentemente reforça que eficiência algorítmica é parte central da engenharia de software séria. E isso fica evidente quando observamos aplicações modernas processando milhões de requisições por segundo.

Um detalhe fascinante é que Big O não mede tempo exato em segundos. Ela mede crescimento relativo. Isso significa que:
- O(1) continua praticamente constante;
- O(log n) cresce lentamente;
- O(n) cresce linearmente;
- O(n²) começa inocente e depois vira um incêndio computacional.
E é aqui que muitos códigos “aparentemente normais” começam a envelhecer mal.
Por que Big O define se seu código é ruim
Existe um momento extremamente desconfortável na vida de todo desenvolvedor. O sistema funciona perfeitamente em ambiente local. Os testes passam. O deploy sobe. Tudo parece ótimo. Então o banco cresce, o tráfego aumenta e o CPU começa a parecer um motor de foguete tentando sobreviver emocionalmente.
Esse colapso geralmente não acontece porque a linguagem é ruim. Nem porque a nuvem falhou. Ele acontece porque algum algoritmo escalou pessimamente.
Veja este exemplo clássico em Python:
def find_duplicate(numbers):
for i in numbers:
for j in numbers:
if i == j:
pass
Esse algoritmo possui complexidade O(n²). Isso significa que dobrar a entrada pode quadruplicar o número de operações.
Agora compare com uma abordagem melhor:
def find_duplicate(numbers):
seen = set()
for n in numbers:
if n in seen:
return True
seen.add(n)
return False
Aqui temos algo próximo de O(n). A diferença prática entre esses dois algoritmos pode representar segundos contra horas dependendo da escala.
É exatamente nesse ponto que muitos desenvolvedores têm um momento importante de clareza: computadores rápidos não salvam algoritmos ruins para sempre.
Entendendo as principais complexidades
O(1): Complexidade constante
Esse é o sonho computacional. O tempo não muda significativamente mesmo com entradas maiores.
Exemplo:
arr = [1, 2, 3]
print(arr[0])
Acesso direto em array normalmente é O(1). O computador sabe exatamente onde o dado está na memória.
O(log n): Crescimento extremamente eficiente
Algoritmos logarítmicos são absurdamente poderosos. Busca binária é o exemplo clássico.
def binary_search(arr, target):
left = 0
right = len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
if arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
A cada iteração, metade do problema desaparece. É quase magia matemática. Yann LeCun já comentou em entrevistas que eficiência computacional continua sendo essencial mesmo na era da IA massiva, porque escala destrói desperdícios rapidamente.
O(n): Crescimento linear
Aqui o custo cresce proporcionalmente à entrada.
for item in items:
print(item)
Normalmente aceitável para muitos cenários.
O(n²): O vilão silencioso
O famoso nested loop.
for i in items:
for j in items:
print(i, j)
Esse padrão parece inocente em pequenos testes. Em produção, vira uma máquina de sofrimento térmico.
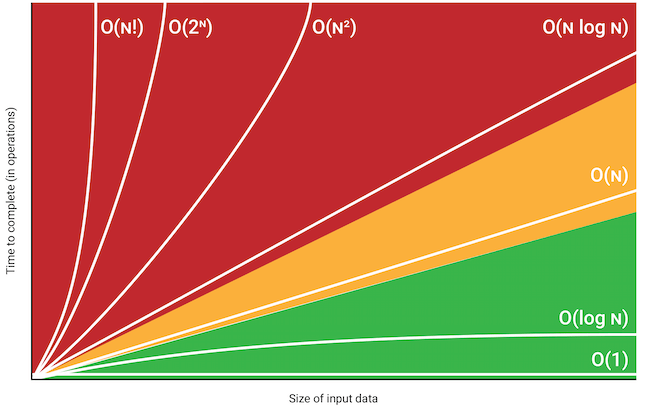
Tabela comparativa das complexidades
| Complexidade | Nome | Escalabilidade | Exemplo |
|---|---|---|---|
| O(1) | Constante | Excelente | HashMap |
| O(log n) | Logarítmica | Muito eficiente | Busca binária |
| O(n) | Linear | Boa | Loop simples |
| O(n log n) | Linearítmica | Muito boa | Merge Sort |
| O(n²) | Quadrática | Ruim em escala | Loops aninhados |
| O(2^n) | Exponencial | Catastrófica | Recursão ingênua |
O mais assustador é que diferenças aparentemente pequenas explodem em larga escala. Um algoritmo O(n²) processando 1 milhão de itens pode se transformar em um evento astronômico digno de observação científica.
O que acontece “por trás dos panos”
Big O existe porque hardware possui limites físicos reais. CPU, cache, RAM, leitura de disco e largura de banda não são infinitos. Cada loop adicional significa:
- mais instruções;
- mais acessos à memória;
- mais cache miss;
- mais ciclos de CPU;
- mais consumo energético.
Programadores iniciantes frequentemente ignoram cache locality, branch prediction e acesso sequencial de memória. Só que CPUs modernas dependem fortemente disso.
Um algoritmo mal estruturado pode:
- destruir performance de cache;
- aumentar garbage collection;
- gerar lock contention;
- degradar paralelismo.
Em sistemas distribuídos, o problema piora. Complexidade ruim multiplicada por rede cria gargalos quase cômicos.
Existe uma frase famosa atribuída a Knuth:
“Premature optimization is the root of all evil.”
Muita gente interpreta isso errado. A frase não significa ignorar desempenho. Ela significa não otimizar sem necessidade. Mas ignorar completamente complexidade algorítmica é outro extremo igualmente perigoso.
Como Big O impacta Inteligência Artificial
Esse assunto fica ainda mais interessante em IA.
Treinar modelos gigantes envolve:
- multiplicação de matrizes;
- busca vetorial;
- processamento paralelo;
- operações distribuídas.
Tudo depende brutalmente de eficiência computacional.
Modelos modernos como transformers só se tornaram possíveis porque pesquisadores encontraram formas eficientes de paralelizar operações matemáticas massivas.
Inclusive, muita inovação em IA não vem apenas de “modelos mais inteligentes”, mas de algoritmos mais eficientes.

O erro clássico de desenvolvedores iniciantes
Existe um comportamento muito comum: priorizar “funciona” sem pensar em escalabilidade.
O problema é que sistemas raramente permanecem pequenos.
Hoje:
- 100 usuários.
Amanhã:
- 1 milhão.
Hoje:
- 1 MB de dados.
Depois:
- 500 GB.
É exatamente aí que algoritmos ruins revelam sua verdadeira natureza.
Na minha experiência como professor em universidade, um dos maiores saltos de maturidade acontece quando estudantes param de perguntar apenas:
“Meu código funciona?”
e começam a perguntar:
“Meu código escala?”
Essa mudança mental separa programadores iniciantes de engenheiros de software reais.
Como identificar gargalos rapidamente
Alguns sinais clássicos indicam problemas de complexidade:
- loops aninhados excessivos;
- buscas repetidas em listas;
- consultas N+1 em bancos;
- recursões mal planejadas;
- processamento redundante;
- ordenações desnecessárias.
Veja um exemplo clássico ruim em JavaScript:
const users = [...];
const posts = [...];
users.forEach(user => {
posts.forEach(post => {
if (post.userId === user.id) {
console.log(post);
}
});
});
Isso escala pessimamente.
Versão otimizada:
const postsMap = {};
posts.forEach(post => {
postsMap[post.userId] = post;
});
users.forEach(user => {
console.log(postsMap[user.id]);
});
Aqui reduzimos buscas repetidas drasticamente.
Big O e entrevistas técnicas
Se você pretende trabalhar em empresas de tecnologia maiores, Big O aparece literalmente em todo lugar:
- entrevistas;
- LeetCode;
- HackerRank;
- sistemas distribuídos;
- arquitetura backend;
- IA;
- bancos de dados.
Isso acontece porque complexidade revela qualidade de raciocínio computacional.
Empresas querem desenvolvedores que entendam custo computacional antes do problema virar prejuízo financeiro.
E sim, existe um certo humor involuntário nisso tudo: muitos sistemas milionários acabam sofrendo porque alguém decidiu usar três loops aninhados “só temporariamente”.

Por que linguagens modernas escondem o problema
Python, JavaScript e frameworks modernos facilitaram absurdamente o desenvolvimento. Isso é maravilhoso. Mas também criou um efeito colateral: muitos desenvolvedores não percebem o custo real das operações.
Exemplo:
if item in huge_list:
Parece simples. Mas em listas gigantes isso pode virar O(n).
Agora compare:
if item in huge_set:
Sets usam hash tables. O comportamento médio tende a O(1).
Uma simples troca de estrutura de dados pode mudar completamente a performance do sistema.
É quase como trocar bicicleta por teletransporte algorítmico.
Como evoluir de verdade em algoritmos
A melhor forma de aprender Big O não é decorar fórmulas. É observar comportamento computacional real.
Pratique:
- arrays;
- hash maps;
- árvores;
- grafos;
- sorting;
- recursion;
- dynamic programming.
Leia código de sistemas grandes. Observe bibliotecas performáticas. Entenda por que certas estruturas existem.
Cormen, no clássico Introduction to Algorithms, mostra algo essencial: algoritmos são engenharia matemática aplicada ao mundo real.
E isso continua absurdamente atual.
CTA: Aprofunde sua visão técnica
Se você quer evoluir em programação, IA, automação e engenharia de software moderna, vale explorar conteúdos avançados em ia.pro.br.
O verdadeiro superpoder dos grandes programadores
Grandes desenvolvedores não apenas escrevem código funcional. Eles entendem comportamento computacional emergente.
Eles antecipam:
- gargalos;
- crescimento;
- concorrência;
- memória;
- custo computacional.
Big O é uma ferramenta mental para enxergar o futuro do sistema antes que ele exploda em produção às três da manhã.
E sinceramente, poucas sensações na engenharia de software são tão dolorosas quanto descobrir que seu algoritmo “perfeito” virou um aquecedor industrial depois que a base de usuários cresceu.
FAQ: Perguntas Frequentes sobre Big O Notation
Big O mede velocidade exata?
Não. Ela mede crescimento relativo do custo computacional conforme a entrada aumenta.
O(n²) sempre é ruim?
Nem sempre. Para conjuntos pequenos pode ser aceitável. O problema aparece em escala maior.
Qual complexidade é considerada ideal?
O(1), O(log n) e O(n) normalmente são excelentes dependendo do contexto.
Big O importa em IA?
Muito. Modelos modernos dependem profundamente de eficiência algorítmica e paralelização.
Python é lento por causa de Big O?
Não necessariamente. Muitas operações internas do Python são altamente otimizadas.
Preciso decorar todas as complexidades?
Não. O mais importante é desenvolver intuição sobre crescimento computacional.
CTA Final: Domine computação além da superfície
Programação moderna não é apenas escrever código. É entender sistemas, algoritmos, memória, escalabilidade e comportamento computacional. Para aprofundar estudos em IA e engenharia moderna, explore ia.pro.br.
Referências Bibliográficas e Técnicas
- Donald Knuth — The Art of Computer Programming.
- Thomas H. Cormen — Introduction to Algorithms.
- Robert Sedgewick — Algorithms.
- Steven Skiena — The Algorithm Design Manual.
- Peter Norvig; Stuart Russell — Artificial Intelligence: A Modern Approach.
- Brian Kernighan; Dennis Ritchie — The C Programming Language.
- Jon Bentley — Programming Pearls.
- Andrew Tanenbaum — Modern Operating Systems.
- MIT OpenCourseWare Algorithms
- Stanford Algorithms Courses
- GeeksForGeeks Big O Guide
- CPython Time Complexity Wiki
Créditos e inspirações técnicas: Professor Maiquel Gomes - maiquelgomes.com.br e ia.pro.br.
Aprenda inglês Técnico em ewc.com.br











0 Comentários